Results for ""
DETaiLED 4 Min Read Apr 12, 2021
DETaiLED - Easy language translation using mBART-50 and Hugging Face

With almost 7000 languages coexisting in our world, communication is the only medium that connects all of us entirely. As we transcend towards togetherness and mutuality with time, language translation provides a critical cultural and economical bridge between people from different countries and ethnic groups.
Thus, needless to say, machine translation is one of the most fascinating and interesting fields in AI. It is essentially used for automatic translation from one language to another. Very recently, while looking for a gripping translation project to quench my curiosity, I discovered mBART 50, a newly released (and rather fascinating) open-source model by Facebook and Hugging Face. It allows you to translate your text to or between 50 languages.
We can do translation with mBART 50 model using the Huggingface library and a few simple lines of the Python code without using any API, or paid cloud services. It is easy to translate the text from one language to another language.
mBart is a multilingual encoder-decoder (sequence-to-sequence) model primarily intended for translation tasks built by Facebook. Model Architecture is beyond the scope of this blog. For detailed MBART 50 architecture, please check out its research paper.
In this blog, we see how to translate the text into other languages using Hugging Face transformers (version 4.4.2) with a simple line of codes.
Installing Transformer Library

SentencePiece is an unsupervised text tokenizer and detokenizer mainly for Neural Network-based text generation systems where the vocabulary size is predetermined prior to the neural model training. For more details, please check this Github.

MBart-50 has its own tokenizer MBart50Tokenizer. I am going to translate English to Tamil and English to French. Let’s start with English to Tamil first.
Before that, we need to download the mBART 50 and the tokenizer model.
Downloading the mBART 50 model and the tokenizer
We are using mBART large 50 many to many models
Here, src_lang is a source language. We are translating English to Tamil, hence our source language is English. mBART 50 supports 50 different languages. It supports many regional Indian languages as well. For more information, you can check the documentation and code that has been given for each language. Using ‘en_XX’ for English.
Giving the sample text into a tokenizer and assigned to model_inputs variable. Also, we can specify whether we need a PyTorch tensor (pt) or a TensorFlow tensor. Here, I specified PyTorch tensor.
The next step is to generate the tokens. We have model input and need to specify which language we need to translate. Here, we are translating into Tamil, so it is “ta_IN”.
Now we can decode the tokens using tokenizer decode.

Output

English to French Translation
I used the same code, except changed the language into french ‘fr_XX’

Output
It seems the model did a pretty good translation. Let’s compare the above examples with Google Translate
English to Tamil — Google Translate

English to French — Google Translate
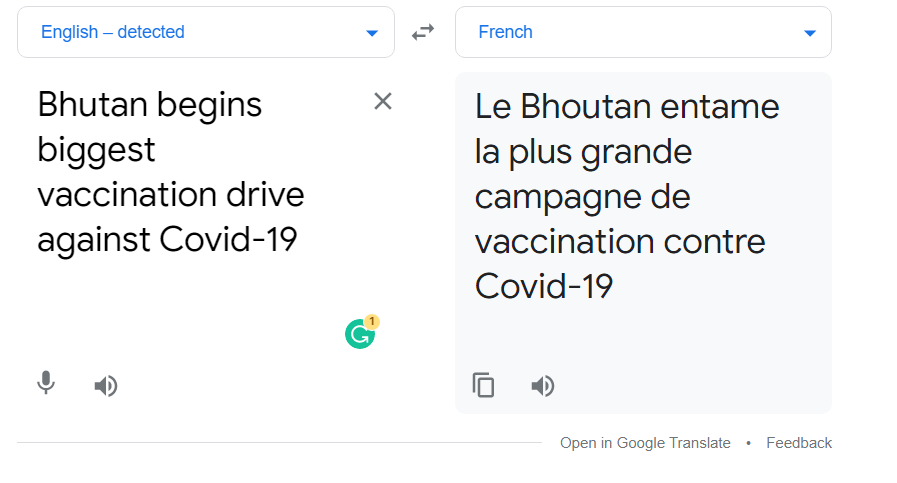
It seems the model did a pretty good job. If we check the above examples with Google Translate, both the results are nearly equal. We can change the input to 50 different languages while translating our text.
In addition, you can check the documentation for more language codes and experiment with them yourself. You can also try with long texts and see how it turns out to be.
You can find the entire code and data in my GitHub repo.




