Results for ""
AI Research 4 Min Read Feb 22, 2023
AI Insights - Exploring shape-aware text-driven layered video editing tool

A new AI study proposes a shape-aware text-driven layered video editing tool from the University of Maryland.
The use of AI in computer science has changed how video editing is done. Video editing is changing and rearranging video clips to achieve a goal. Tools for editing videos powered by AI make the post-production process faster and more effective.
Deep learning algorithms have enabled AI to fix colours, track objects, and make content automatically. In addition, AI can suggest edits and transitions that would make the final video look and feel better by looking for patterns in the data. AI-based tools can also help editors organise and classify large video libraries, making it easier to find the needed footage. As a result, using AI to edit videos could reduce the time and work required to create high-quality videos while opening up new creative possibilities.
In recent years, the application of GANs in text-guided image generation and manipulation has advanced significantly. Text-to-image generation models such as DALL-E and more modern approaches employing pre-trained CLIP embeddings have proven effective. In text-guided image production and modification, diffusion models, such as Stable Diffusion, have succeeded, resulting in various creative applications. Yet, video editing requires temporal consistency in addition to spatial precision.
Their paper extends to consistent video editing and the semantic picture editing capabilities of the state-of-the-art text-to-image model Stable Diffusion.
Below is a picture of the pipeline for the proposed architecture.
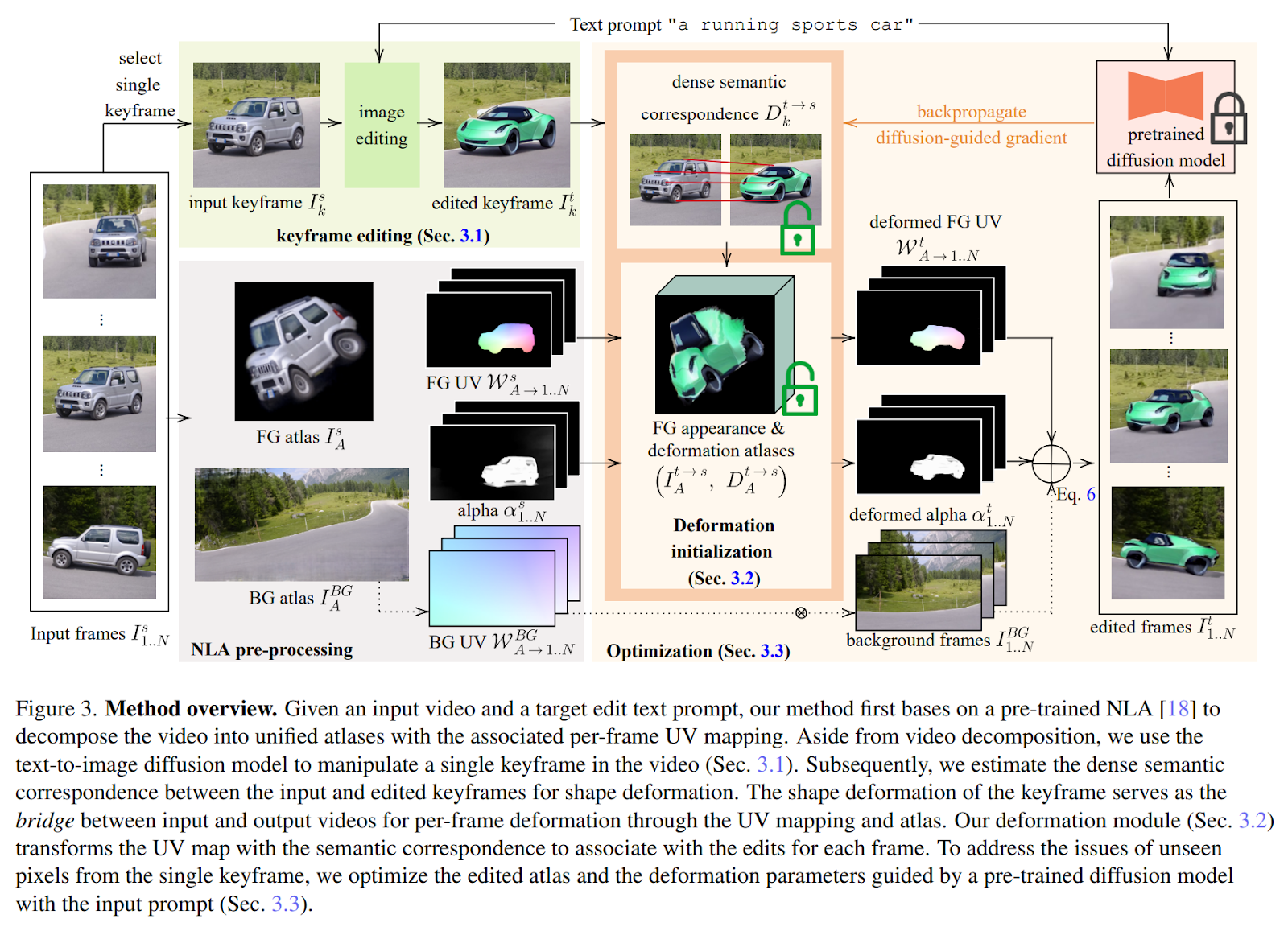
Image source: Shape-aware Text-driven Layered Video Editing
The proposed shape-aware video editing method takes an input video and a text prompt. It makes a consistent video with changes in look and shape while keeping the motion in the input video. For temporal consistency, the method uses a pre-trained NLA (Non-Linear Atlas) to separate the input video into unified atlases of the background (BG) and foreground (FG) with per-frame UV mapping. After the video is broken down, a text-to-image diffusion model changes a single keyframe (Stable Diffusion).
The model estimated dense semantic correspondence using this updated keyframe. Then, it makes it possible to change the shape. This step is delicate because it creates the shape deformation vector applied to the target image to keep the same look over time. Since the UV mapping and atlas link the edits to each frame, this shape deformation is the basis for per-frame deformation. A pre-trained diffusion model is also used to ensure that the output video is seamless and has no pixels that can't be seen. Furthermore, the authors say that the proposed approach leads to a reliable video editing tool that gives the video a look you want and lets you edit shapes consistently.
Conclusion
In video editing applications, temporal consistency is vital. Previous work on layered video representation permits continuous propagation of modifications to each frame. However, due to the limitation of employing a fixed UV mapping field for texture atlas, these methods can only modify the appearance of an object and not its shape. The researchers describe a text-driven, shape-aware video editing solution to address this issue. First, the deformation field between the input and edited keyframe is propagated to all frames for video editing shape changes. The researchers then use a pre-trained text-conditioned diffusion model to refine form distortion and fill in unseen regions.
For more information:




