Results for ""
K-Nearest Neighbour Algorithm 4 Min Read Jun 29, 2020
DETaiLED - Introduction to K-Nearest Neighbours (KNN) - Supervised Machine Learning Algorithm

What is KNN?
KNN classification algorithm classifies a data point into the category which is most common among its neighbouring data points. If a datapoint is surrounded mostly by a particular category of data points say “Red dots”, then the datapoint under consideration is very likely to be a red dot as well.
The ‘K’ in KNN is the number of nearest neighbours that are taken into account in the voting process to assess the majority.
Let’s consider two data points, 1) circle 2) star.

Suppose, if we want to test the new data point and predict whether it belongs to a circle or star category?
OK, how do we predict or classify the new data point?

First, we need to find the distance between new data points and the nearest data points by using similarity measures. Similarity measures are nothing but distance between two data points. There are different distance measures available. Some of the popular ones are Euclidean, Manhattan, Minkowski and Hamming distance methods. Euclidean distance is widely used. Hamming distance used for category variables.
Next, we need to find out what the neighbours are in the above example. Let’s assume K = 4. Then the new data points are classified by the majority of votes from it’s four neighbours. Here, the new data point is circle as three out of four neighbours are circle.
This is the working process of the K-NN algorithm.
How do we select the ‘k’ value?
Now the next question is how to choose the optimal value of ‘k’. ‘k’ is a hyperparameter and finding the same is not an easy task. There is no concrete method to find ‘k’ value. We have to assume various values by trial and error method.
We can find the optimal value of ‘k’ using cross validation. By taking a small portion of data from the training dataset and evaluate different values of ‘k’. With the help of different values of ‘k’, we can predict the label for every instance in the validation dataset. Then, identify the best accuracy on the validation dataset corresponding to the ‘k’ value. Take the corresponding ‘k’ value which gives best accuracy as a final ‘k’ value and set into the algorithm. This will also minimize the validation error. In a simpler term, generate different models with different ‘k’ values and check the model accuracy.
Some of the things to be noted:
Small ‘k’ values - It will be noisy and have a high influence on the result.
High ‘k’ values - It will have smoother decision boundaries which gives high bias, low variance and computationally expensive.
Alway choose an odd value of ‘k’ if the number of target classes is even.
Let’s consider one more example. Credit card payment default. Here, we have a list of customers, their age, amount spent by them using a credit card, and their payment default status yes or no.
Here, we need to predict customer ‘Alex’ default status

First step: Calculate the similarity measures for all the data points by using Euclidean distance.
Euclidean distance = dist((x, y), (a, b)) = Sqrt(x - a)² + (y - b)²
x -> Alex age -> 50
y-> Amount spent by Alex -> 23453
a is a data point of other customer’s age.
b is a data point of amount spent by other customers
Example calculate the distance for customer jack,
distance = Sqrt(50 -39)2 + (23453 - 50000)2
distance = 26547
We need to calculate the distance for all other customers.
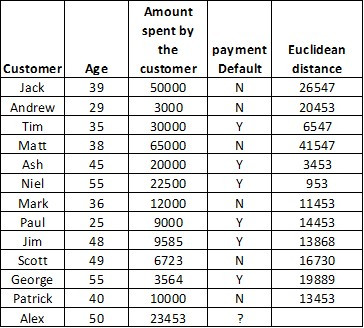
Now, let’s assume k = 5. Find the minimum euclidean distance and rank in ascending order. Out of 5 neighbours, three customers' payment default is yes and it carries a majority vote. So the Alex payment default status is Yes.

K-NN is a lazy learning algorithm because it doesn’t learn a discriminative function from the training data but “memorizes” the training dataset instead.
Advantage of KNN
- Very simple algorithm and easy to implement
- It supports both classification and regression problems
- It handles all the multi class cases
Disadvantage of KNN
- Computation time and cost is quite high
- Required larger memory to store the data




