Results for ""
Data Annotation 7 Min Read Aug 21, 2023
User Submission - Introduction to Reinforcement Learning from Human Feedback

In the vast realm of artificial intelligence, a groundbreaking concept has emerged: Reinforcement Learning from Human Feedback (RLHF). Imagine a world where AI agents learn complex tasks efficiently by incorporating human expertise. It’s a paradigm shift that combines the power of human guidance with the learning capabilities of machines. Let's delve into the world of RLHF, exploring its mechanism, benefits, and the exciting possibilities it holds for the future.
What is Reinforcement learning?
Reinforcement learning is the training of machine learning models to make a sequence of decisions. The agent learns to achieve a goal in an uncertain, potentially complex environment. In reinforcement learning, artificial intelligence faces a game-like situation. The computer employs trial and error to come up with a solution to the problem. To get the machine to do what the programmer wants, artificial intelligence gets either rewards or penalties for the actions it performs. Its goal is to maximize the total reward.
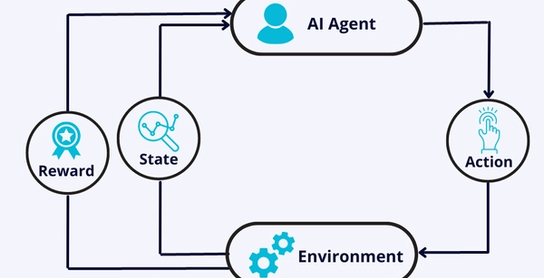
Example of Reinforcement Learning: Consider a robot trying to learn how to navigate a maze. The maze is the environment, and the robot is the RL agent. At the beginning of training, the robot explores the maze by taking random actions and receiving rewards or penalties based on its progress. For instance, it receives a positive reward when it moves closer to the maze's exit and a negative reward for hitting walls or moving away from the exit. Over time, the robot learns from these rewards and penalties, updating its policy to take actions that lead to higher cumulative rewards, eventually learning the optimal path to reach the maze's exit.
What is Reinforcement learning from human feedback?
Reinforcement learning from human feedback (RLHF) is a subfield of artificial intelligence (AI) that combines the power of human guidance with machine learning algorithms. It involves training an AI agent to make decisions by receiving feedback. Unlike traditional reinforcement learning (RL), where the agent learns through trial and error, RLHF enables faster and more targeted learning by leveraging human expertise.
The difference between RL and RLHF lies in the source of feedback. Reinforcement Learning with Human Feedback (RLHF) is a variant of RL that incorporates feedback from human experts in addition to the traditional reward signal from the environment. Human feedback can provide additional information to guide the agent's learning, especially in situations where the reward signal from the environment is sparse or challenging to define. RL relies on autonomous exploration, while RLHF integrates human guidance to accelerate learning. RLHF acts as a teacher, enhancing the learning process by leveraging human expertise. For that purpose, it uses observation space, the set of all possible inputs.
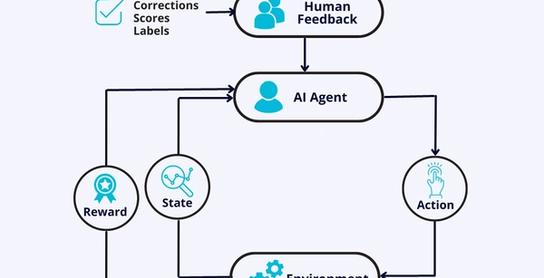
In the example of "Teaching a Robot to Sort Objects" using Reinforcement Learning with Human Feedback (RLHF), the robot is initially tasked with sorting objects, such as colored blocks, with no prior knowledge of how to do so effectively. Through Reinforcement Learning, the robot interacts with the environment and receives rewards for successful sorting and penalties for mistakes. Over time, it learns to improve its sorting skills based on trial and error. To expedite the learning process and provide nuanced guidance, a human supervisor intervenes and provides direct feedback and corrections when the robot faces challenges. The supervisor assists the robot by pointing out correct colors and positions, suggesting alternative approaches, and demonstrating the proper sorting order. The robot incorporates this human feedback into its learning, refining its policy, and gradually becoming proficient at sorting the objects accurately and efficiently. The combination of Reinforcement Learning with Human Feedback ensures that the robot gains a deeper understanding of the task and achieves better performance compared to traditional RL training alone.
How does RLHF work?
RLHF training is done in three phases:
Initial Phase
In the first step of RLHF training, an existing model is chosen as the main model. This model is used to identify and label correct behaviors. The model is trained on a large corpus of data collected and processed. The advantage of using a pre-trained model
is that it saves time since collecting enough data for training from scratch can be time-consuming.
Human Feedback
Once the initial model is trained, human testers provide feedback on its performance. These human evaluators assess the quality and accuracy of the outputs generated by the model. They assign a quality or accuracy score to various model-generated results. This human feedback is crucial as it helps in creating rewards for reinforcement learning.
Reinforcement Learning
In the final step, reinforcement learning is applied to fine-tune the reward model. The reward model is adjusted based on the outputs from the main model and the quality scores received from human testers. The main model uses this refined reward model to improve its performance on future tasks, making it more accurate and effective.
RLHF is an iterative process, where human feedback and reinforcement learning are repeated in a loop, continuously improving the model's performance and enhancing its ability to handle various tasks.
The Power of Human Expertise
RLHF capitalizes on the abundance of human expertise to optimize systems, boost performance, and elevate decision-making. Through the utilization of human guidance, RLHF unlocks a number of advantages that propel AI to unprecedented achievements:
Accelerated Training
RLHF revolutionizes the training of reinforcement learning models by leveraging human feedback to guide the learning process. Instead of relying solely on autonomous exploration, human expertise directs AI agents, leading to faster adaptation to various domains and contexts. This saves valuable time, allowing AI systems to swiftly become proficient in specific tasks.
Improved Performance
With RLHF, reinforcement learning models receive valuable human feedback, enabling refinement and fine-tuning. Flaws are addressed, and decision-making capabilities are enhanced. Whether it's chatbot responses, recommendation systems, or customer service interactions, RLHF ensures AI delivers high-quality outcomes that better satisfy users' needs and expectations.
Reduced Cost and Risk
RLHF minimizes the costs and risks associated with training RL models from scratch. By leveraging human expertise, expensive trial and error can be circumvented. In domains like drug discovery, RLHF expedites the identification of promising candidate molecules for testing, accelerating the screening process and reducing both time and costs.
Enhanced Safety and Ethics
RLHF empowers reinforcement learning models with ethical decision-making capabilities. By incorporating human feedback, AI agents can make informed and safe choices, particularly in fields like medicine, where patient safety and values are paramount. RLHF ensures that AI aligns with ethical standards and adheres to user-defined guidelines.
Increased User Satisfaction
RLHF enables personalized experiences by incorporating user feedback and preferences into reinforcement learning models. AI systems can deliver tailored solutions that resonate with individual users, improving overall satisfaction. In recommendation systems, RLHF optimizes suggestions, leading to higher user engagement and content relevance.
Continuous Learning and Adaptation
RLHF ensures that reinforcement learning models remain relevant in ever-changing conditions. Regular human feedback enables AI agents to adapt and adjust their policies, allowing them to identify new patterns and make better decisions. Models, such as fraud detection systems, can continuously evolve and effectively detect emerging fraud patterns.
Conclusion
The power of human expertise in RLHF unlocks new possibilities for AI, transforming its capabilities in diverse applications. From accelerated training to enhanced safety and increased user satisfaction, RLHF paves the way for AI systems that are not only efficient but also ethical and adaptable. As AI and human collaboration continue to evolve, RLHF stands as a testament to the potential of combining the best of human insight and machine learning to shape a smarter, more responsible future.
If you are seeking to train your model with Reinforcement Learning with Human Feedback (RLHF), TagX offers comprehensive data solutions and invaluable human expertise to accelerate your AI development. With our team of skilled evaluators and trainers,
Sources of Article
https://www.tagxdata.com/introduction-to-reinforcement-learning-from-human-feedback




