Results for ""
AI Research Oct 26, 2020 CANADA
AI learning adopts LO-shot learning
Machine learning is an arduous task. Artificial Intelligence (AI) algorithms need a mammoth amount of data to be trained to perform simple tasks - which makes the technology expensive, takes longer to be developed and sometimes difficult. It also is very different from human learning, something which AI algorithms constantly try to emulate. For example, a child will learn to recognise a horse for a lifetime, after seeing one example, or a few at the maximum; but for an AI to achieve the same feet, it will need to be trained on thousands of images.
In fact, humans sometimes don't need any examples to identify something. A mere description of an object can help us identify the said object. For example, children can identify a unicorn the very first time they see an image after being shown photos of a rhino and a horse and told that a unicorn is a creature somewhere in between. The same is not the case with machine learning.
The Canadian researchers are taking this challenge head-on. In a new paper published by the University of Waterloo, Ontario suggests a process which may allow an AI algorithm to be able to learn and recognise more objects than that it has been trained on. The researchers have named this process the "less than one" shot or LO-shot learning.
The researchers demonstrated this approach with the MNIST dataset that has 60,000 images of written digits from 0 to 9. The researchers shrank the dataset down to five images by creating images that blend several digits together and then feeding it into the training with hybrid or soft labels. “If you think about the digit 3, it kind of also looks like the digit 8 but nothing like the digit 7,” says Ilia Sucholutsky, a PhD student at Waterloo and lead author of the paper. “Soft labels try to capture these shared features. So instead of telling the machine, ‘This image is the digit 3,’ we say, ‘This image is 60% the digit 3, 30% the digit 8, and 10% the digit 0.’”
Once they achieved a certain level of success with MNIST through LO-shot learning, the researchers explored other categories to perform similar experiments where they can train an AI algorithm with a tiny number of examples.
However, they were met with little success there. With carefully engineered soft labels, even two examples could theoretically encode any number of categories. “With two points, you can separate a thousand classes or 10,000 classes or a million classes,” Sucholutsky says.
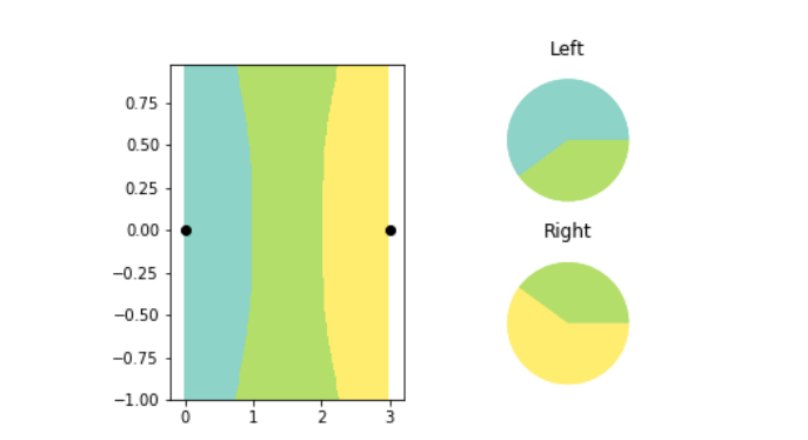
The paper demonstrates this statement in their latest paper using a mathematical exploration, using the concept - k-nearest neighbours (kNN), an AI algorithm that classifies objects on a graph. The kNN understands the difference between two objects by referring to the features assigned to refer to both on its x-axis and y-axis. The kNN algorithm then plots all the data points on a 2D chart and draws a boundary line straight down the middle between, dividing the data set into two classes. The algorithm then bifurcates new data points represent one or the other based on which side of the line they fall on.
The researchers utilised this concept to explore LO-shot learning by creating a series of tiny synthetic datasets with carefully soft-labelling them. They observed that the kNN plot was able to successfully plot and split categories into data points. The researchers also had control over where the kNN boundary lines fell. By adjusting the soft labels, they could enable the kNN algorithm to draw precise patterns in the shape of flowers.
However, as of now, these are merely theoretical explorations and come with limits. While LO-shot learning will be able to transfer to more complex algorithms, creating apt soft-labelled examples is an arduous task. The kNN algorithm is interpretable and visual, enabling humans to design the labels. however, neural networks are more complicated and impenetrable, meaning the same may not be true. Data distillation, which works for designing soft-labelled examples for neural networks, also has a major disadvantage: it requires you to start with a giant data set in order to shrink it down to something more efficient.
This is what most interests Tongzhou Wang, an MIT PhD student who led the earlier research on data distillation. “The paper builds upon a really novel and important goal: learning powerful models from small data sets,” he says of Sucholutsky’s contribution.
While the research is at its nascent stage and is metted by disbelief from fellow researchers, there is growing excitement that a whole new world may open up to machine learning if the research succeeds on a scale.




